How does it Work?
- Captures Video Frames: The software begins by capturing real-time video frames from an input source, such as a webcam or a pre-recorded video. OpenCV, a popular open-source computer vision library, provides the necessary tools to access video streams and individual frames.
- Hand Detection and Tracking with MediaPipe: MediaPipe, developed by Google, is a powerful framework for building multimodal applied machine learning pipelines. This software utilizes MediaPipe's Hand Tracking module to detect and track hands within each video frame. This process involves identifying key landmarks on the hand, such as fingertips, knuckles, and wrist, using a machine learning-based hand pose estimation model. The model is capable of robustly tracking hands even under various orientations, lighting conditions, and occlusions.
- Hand Gesture Classification: Once MediaPipe successfully tracks the hand landmarks, the software extracts relevant hand features and encodes them into a suitable representation for classification. These features may include the spatial positions of fingers, angles between joints, or any other relevant information that characterizes different hand gestures.
- Translation and Output: Once the classifier determines the most probable hand gesture from the extracted features, S.lang translates it into the corresponding letter or symbol in the chosen sign language. The output is then displayed to the screen for the other user to comprehend.
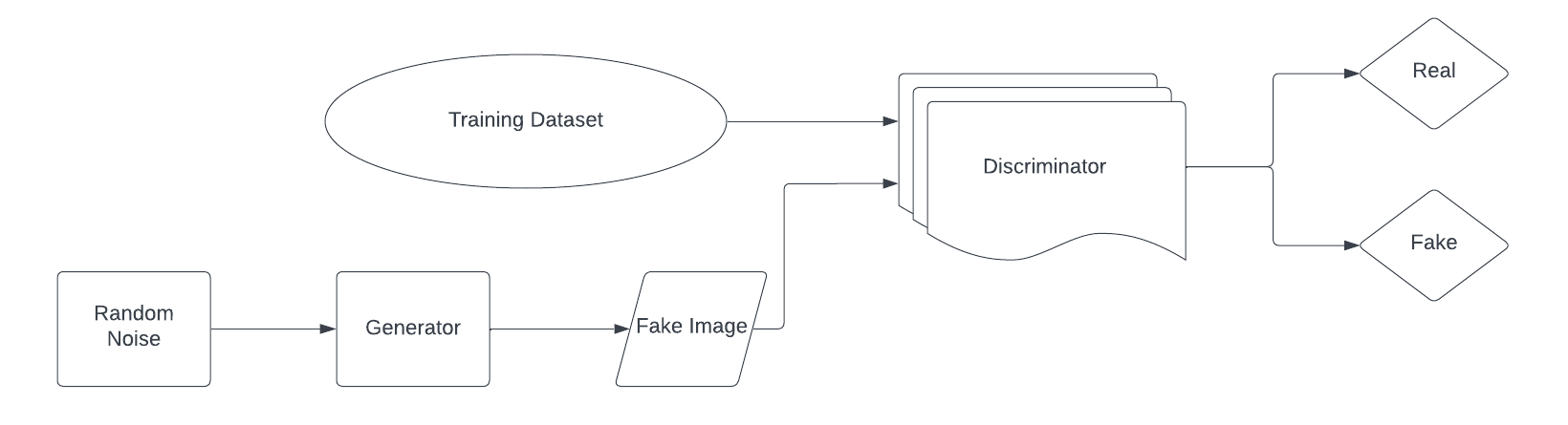
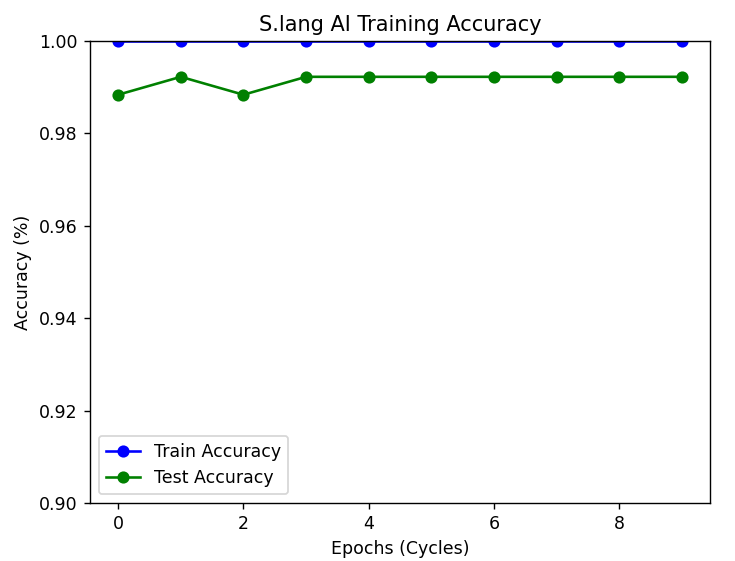
- Text to Gesture As for the other user, if they would like to communicate back in sign language, they would simply input a prompt or their text to generate unique images corresponding to the input text. What makes this possible is our trained GAN model that runs on two neural networks to generate new, replicated instances of data. Read more about it here
- Real-Time Performace One of the key strengths of your software is its real-time performance. By leveraging efficient algorithms and optimizations provided by OpenCV and MediaPipe, this application can process video frames rapidly, providing instantaneous hand gesture recognition and translation.
.jpg)
.jpg)